Why UPS reliability matters more than ever
A zero failure rate doesn’t exist – but in the world of digital services, tolerance to interruption has fallen to zero. Even a few seconds of downtime can result in data loss, service unavailability, or contractual penalties (SLA breaches).
Enterprise and edge data centres must guarantee maximum uptime – approaching 100% – in an environment that is more complex and demanding than ever.
Key challenges driving the need for reliability
- AI and HPC surges – enterprise workloads generate unpredictable and heavy demands, putting power infrastructures under strain.
- Cyber-attacks targeting critical infrastructure – malicious attempts can disable or destabilise power and cooling systems.
- Complex hybrid architectures – with edge computing, multi-site deployments and hybrid cloud models, resilience must span multiple layers.
Consequences for data centres
- Redundant architectures are mandatory – Tier III / IV, 2N, or N+1 configurations are becoming standard to ensure continuity.
- UPS equipment must withstand all power anomalies and ensure uninterrupted continuity, regardless of load behaviour and dynamics.
- “No downtime” maintenance and proactive supervision – predictive monitoring, hot-swappable modules and continuous diagnostics are critical in order to sustain reliability at scale.
In this context, the reliability of modular UPS, quantified by high MTBF values, has become a decisive factor for operators aiming to secure long-term resilience and availability.
What is MTBF in UPS?
The probability of a critical failure (load loss) in the best modular uninterruptible power supply (UPS) is extremely low, thanks to its redundant architecture and the design of its power modules, which operate independently and can isolate any internal fault to prevent propagation.
Nonetheless, random failures of individual power modules can still occur. While these typically do not impact the output of a premium modular UPS, they compromise the system’s redundancy and must be addressed to maintain optimal fault tolerance.
The key issue is the reliability of each power module — the more modules used in the system, the higher the cumulative risk of failure. The UPS's internal failure rate increases with the number of modules and decreases with the MTBF of each one.
Since the number of power modules is determined by the system's power and redundancy requirements, the only way to achieve acceptable overall reliability is to use power modules with a very high MTBF — in other words, an exceptionally low failure rate.
MTBF – Mean Time Between Failures – is the measure of how long a module can run before failing. The higher the MTBF, the lower the failure rate, the more reliable the power module.
Why MTBF is critical for data centres
Over a typical 15-year UPS lifespan, a high MTBF significantly reduces the number of module failures. This reduction not only extends system reliability but also delivers substantial economic benefits and minimises the possible risks associated with module replacement.
In practical terms, higher MTBF means:
- Fewer failures over the lifecycle.
- Lower operating costs thanks to reduced maintenance and replacement needs.
- Improved SLA compliance.
- Greater sustainability.
How MTBF is calculated and certified
Due to the key role of MTBF in ensuring system reliability, it is calculated through in-depth evaluation of module components and subassemblies, using strict statistical methods, supported by a series of targeted tests for mechanical strength, durability and long-term reliability.
To ensure the credibility of the MTBF value, certification must be conducted by an independent laboratory, and validated with real-world field data. This confirms that the predictive MTBF is not merely theoretical but grounded in actual performance.
In other words, reliability is not just a promise — it’s demonstrated through independent testing and verified by field data from many thousands of modules operating in real-world conditions.
Socomec solution: MODULYS XM
MODULYS XM is the ultra-modular UPS designed for complete peace of mind. Its power modules have an MTBF exceeding 1,000,000 hours — four times higher than the market standard. This figure was determined by an independent specialist laboratory following two years of rigorous testing, with official certification available upon request.
After several years and with over 50,000 power modules installed—accumulating more than 1 billion hours of operation—the measured MTBF significantly exceeds 1,000,000 hours, surpassing the initially calculated value. An official report of this measured MTBF, updated every six months, is available upon request.
This result is unique in the UPS industry and can only be achieved by designing power modules that are based on reliability, not cost.
With MODULYS XM, data centres gain:
- Fault-tolerant design.
- Hot-swappable modules for maintenance without downtime.
- Scalability to meet evolving data centre demands.
- Independent certification and regularly updated field reliability data.
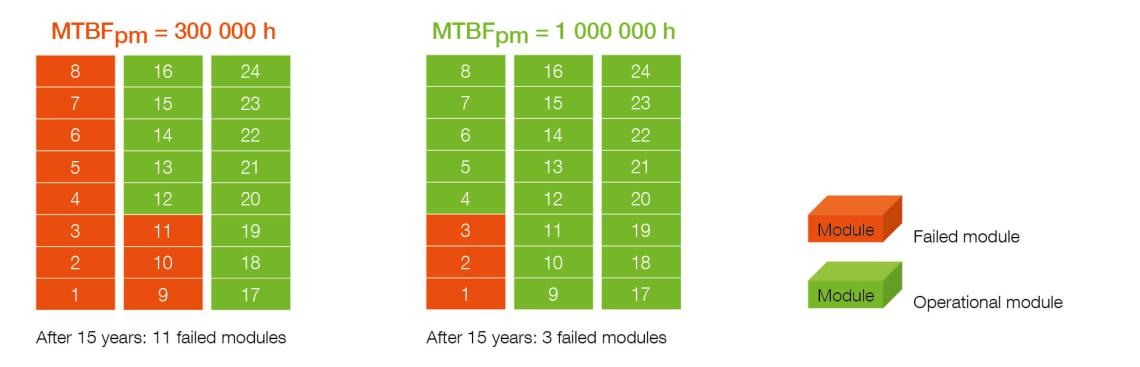
Example: MTBF of 1,000,000 hours in practice
Let’s assume:
- A system of 24 UPS modules
- Each module has an MTBF of 1,000,000 hours
- Expected lifecycle: 15 years = 131,400 hours
Expected failures = (24 × 131,400) ÷ 1,000,000 = ≈3 modules over 15 years.
With a standard modular UPS having 250,000 hours MTBF, the number increases to 12 modules.
This means significant cost savings, fewer risks, and higher system availability.
Extended MTBF explanation
- Calculated MTBF is the result of the analysis of stress factors for each UPS component and sub-system plus stress testing.
- Measured MTBF is taken from real installations and cumulative operating hours.
- Both are essential: calculated values provide predictions, while measured data validates them in real life.
Importantly, MTBF should be considered alongside MTTR (Mean Time to Repair). High MTBF reduces the number of failures, while low MTTR ensures rapid recovery when they occur. Together, they determine the ultimate availability of a UPS system.
FAQ: power modules, UPS failures and MTBF
Are power modules always reliable?
Modern UPS power modules are designed with reliability as a core priority. Certification processes require modules to undergo rigorous stress testing in independent laboratories, where they are subjected to temperature, load and endurance trials. Real-world field data often confirms even higher measured MTBF figures, giving data centre operators confidence that modules will perform over long lifespans. Reliability is also enhanced by design choices: the separation of modules isolates failures, hot-swappable design ensures rapid replacement, and predictive monitoring helps detect anomalies early. With these features, modules are not only reliable individually but also contribute to a highly fault-tolerant UPS system when deployed in parallel. Compared with monolithic UPS designs, modular power units reduce the risk of single points of failure and increase resilience, which is why they are increasingly the standard for enterprise and edge data centres.
How do you know if a UPS is failing?
Signs of UPS failure can appear gradually or suddenly, depending on the cause. Common indicators include frequent alarms, shorter autonomy during power outages, unusual noises from fans or electronics, and visible degradation on batteries (swelling, leakage). Operators may also notice inconsistent performance, such as voltage fluctuations, or repeated alerts in the monitoring software. In advanced systems, predictive monitoring provides early warnings by tracking parameters such as battery impedance, capacitor health, temperature, and load balance. When thresholds are exceeded, the system signals a risk of failure, allowing preventive action. In modular UPS architectures, monitoring is performed at the module level, making it easier to isolate the source of degradation. Detecting failure early is critical: unaddressed, minor anomalies can evolve into unexpected shutdowns that jeopardise uptime. Regular inspections, combined with smart monitoring tools and especially reliable design, are the most effective ways to maintain system reliability.
How is UPS MTBF calculated?
UPS MTBF is determined using a combination of reliability prediction modelling, laboratory stress testing and field data validation. In reliability engineering, the primary estimation is performed through parts-stress analysis in accordance with standards such as IEC 61709, SN 29500, or MIL-HDBK-217F. Each component’s failure rate is derived from reference databases and adjusted using stress factors for temperature, voltage and environment. These component failure rates are then aggregated within a reliability block diagram (RBD) to model the complete UPS architecture, including any redundant (N+1) elements. The resulting system failure rate (λ) provides the calculated MTBF = 1 / λ. Laboratory tests are used to validate or refine these models. Components or modules are subjected to accelerated stress conditions (e.g. elevated temperature, humidity, vibration and cyclic loads) to confirm that degradation mechanisms behave as predicted. These tests support the assumptions used in the reliability model but do not directly determine the MTBF value. Due to the fact that accelerated tests cannot reproduce every field condition, field data from installed systems is also analysed. Actual operating hours and failure counts across large populations provide a measured MTBF, reflecting real-world performance. When a significant installed base exists — thousands of modules operating for millions or billions of cumulative hours — the resulting statistics become highly robust. Independent laboratories such as SERMA or TÜV may audit the methodology and verify data consistency. This dual approach — predicted MTBF (analytical) and measured MTBF (empirical) — ensures that the declared reliability figure is traceable, credible and representative of actual data-centre operating environments.
What is considered a good MTBF?
For UPS power modules, an MTBF above 1,000,000 hours is indeed exceptional. Such a figure indicates an extremely low theoretical failure rate (λ ≈ 1 × 10⁻⁶ failures/hour), but it should always be interpreted within the assumptions of the reliability model — namely, constant failure rate, no deterioration, and ideal installation conditions. For standard modular UPS, the average field MTBF values for UPS power modules are in the 200,000 – 300,000 hour range, depending on component quality, ambient temperature, load profile and maintenance practices. For mission-critical applications such as enterprise or edge data centres, it’s more than important to select UPS systems with the highest MTBF on the market. A dual validation — analytical prediction possibly certified by independent audits (e.g. SERMA or TÜV) plus empirical confirmation based on a significant installed base — ensures that the reliability claim is credible, traceable and representative of real conditions. Ultimately, a “good MTBF” is not an abstract number: it is the one that supports the site’s SLA targets, enables fault-tolerant architectures and minimises the risk and total cost of downtime over the UPS’s lifecycle.